Scyld ClusterWare Design Overview¶
This chapter discusses the design behind Scyld ClusterWare, beginning with a high-level description of the system architecture for the cluster as a whole, including the hardware context, network topologies, data flows, software context, and system level files. From there, the discussion moves into a technical description that includes the compute node boot procedure, the process migration technology, compute node categories and states, and miscellaneous components. Finally, the discussion focuses on the ClusterWare software components, including tools, daemons, clients, and utilities.
As mentioned in the preface, this document assumes a certain level of knowledge from the reader and therefore, it does not cover any system design decisions related to a basic Linux system. In addition, it is assumed the reader has a general understanding of Linux clustering concepts and how the second generation Scyld ClusterWare system differs from the traditional Beowulf. For more information on these topics, see the User’s Guide.
System Architecture¶
Scyld ClusterWare provides a software infrastructure designed specifically to streamline the process of configuring, administering, running, and maintaining commercial production Linux cluster systems. Scyld ClusterWare installs on top of a standard Linux distribution on a single node, allowing that node to function as the control point or “master node” for the entire cluster of “compute nodes”.
This section discusses the Scyld ClusterWare hardware context, network topologies, system data flow, system software context, and system level files.
System Hardware Context¶
A Scyld cluster has three primary components:
The master node
Compute nodes
The cluster private network interface
These components are illustrated in the following block diagram. The remaining element in the diagram is the public/building network interface connected to the master node. This network connection is not required for the cluster to operate properly, and may not even be connected (for example, for security reasons).
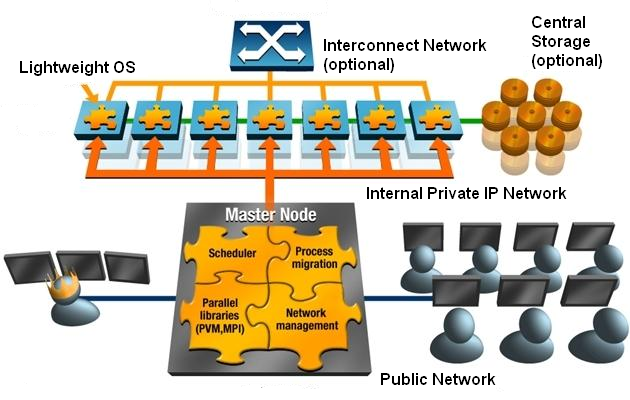
Figure 1. Cluster Configuration
The master node and compute nodes have different roles in Scyld ClusterWare, and thus they have different hardware requirements. The master node is the central administration console for the cluster; it is the machine that all users of the cluster log into for starting their jobs. The master node is responsible for sending these jobs out to the appropriate compute node(s) for execution. The master node also performs all the standard tasks of a Linux machine, such as queuing print jobs or running shells for individual users.
Master Node¶
Given the role of the master node, it is easy to see why its hardware closely resembles that of a standard Linux machine. The master node will typically have the standard human user interface devices such as a monitor, keyboard, and mouse. It may have a fast 3D video card, depending on the cluster’s application.
The master is usually equipped with two network interface cards (NICs). One NIC connects the master to the cluster’s compute nodes over the private cluster network, and the other NIC connects the master to the outside world.
The master should be equipped with enough hard disk space to satisfy the demands of its users and the applications it must execute. The Linux operating system and Scyld ClusterWare together use about 7 GB of disk space. We recommend at least a 20 GB hard disk for the master node.
The master node should contain a minimum of 2 GB of RAM, or enough RAM to avoid swap during normal operations; a minimum of 4 GB is recommended. Having to swap programs to disk will degrade performance significantly, and RAM is relatively cheap.
Any network attached storage should be connected to both the private cluster network and the public network through separate interfaces.
In addition, if you plan to create boot CDs for your compute nodes, the master node requires a CD-RW or writeable DVD drive.
Compute Nodes¶
In contrast to the master node, the compute nodes are single-purpose machines. Their role is to run the jobs sent to them by the master node. If the cluster is viewed as a single large-scale parallel computer, then the compute nodes are its CPU and memory resources. They don’t have any login capabilities, other than optionally accepting ssh connections from the master node, and aren’t running many of the daemons typically found on a standard Linux box. These nodes don’t need a monitor, keyboard, or mouse.
Video cards aren’t required for compute nodes either (but may be required by the BIOS). However, having an inexpensive video card installed may prove cost effective when debugging hardware problems.
To facilitate debugging of hardware and software configuration problems on compute nodes, Scyld ClusterWare provides forwarding of all kernel log messages to the master’s log, and all messages generated while booting a compute node are also forwarded to the master node. Another hardware debug solution is to use a serial port connection back to the master node from the compute nodes. The kernel command line options for a compute node can be configured to display all boot information to the serial port. See Compute node command-line options or details about the console= configuration setting..
Compute node RAM requirements are dependent upon the needs of the jobs that execute on the node. Compute node physical memory is shared between its RAM-based root filesystem (rootfs) and the runtime memory needs of user applications and the kernel itself. As more space is consumed by the root filesystem for files, less physical memory is available to applications’ virtual memory and kernel physical memory, a shortage of which leads to Out-Of-Memory (OOM) events that result in application failure(s) and potentially total node failure.
Various remedies exist if the workloads fill the root filesystem or trigger Out-Of-Memory events, including adding RAM to the node and/or adding a local harddrive, which can be configured to add adequate swap space (which expands the available virtual memory capacity) and/or to add local filesystems (to reduce the demands on the RAM-based root filesystem). Even if local swap space is available and sufficient to avoid OOM events, optimal performance will only be achieved when there is sufficient physical memory to avoid swapping in the first place. See Compute Node Failure for a broader discussion of node failures, and Compute node command-line options for a discussion of the rootfs_size= configuration setting that limits the maximum size of the root filesystem.
A harddrive is not a required component for a compute node. If employed, we recommend using such local storage for data that can be easily re-created, such as swap space, scratch storage, or local copies of globally-available data.
If the compute nodes do not support PXE boot, a bootable CD-ROM drive is required.
Network Topologies¶
For many applications that will be run on Scyld ClusterWare, an inexpensive Ethernet network is all that is needed. Other applications might require multiple networks to obtain the best performance; these applications generally fall into two categories, “message intensive” and “server intensive”. The following sections describe a minimal network configuration, a performance network for “message intensive” applications, and a server network for “server intensive” applications.
Minimal Network Configuration¶
Scyld ClusterWare requires that at least one IP network be installed to enable master and compute node communications. This network can range in speed from 10 Mbps (Fast Ethernet) to over 1 Gbps, depending on cost and performance requirements.
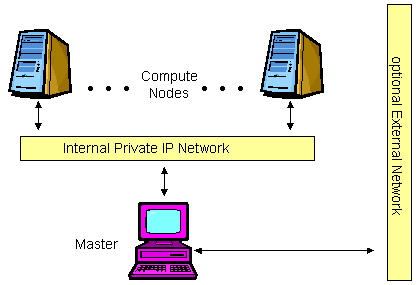
Figure 2. Minimal Network Configuration
Performance Network Configuration¶
The performance network configuration is intended for applications that can benefit from the low message latency of proprietary networks like Infiniband, TOE Ethernet, or RDMA Ethernet. These networks can optionally run without the overhead of an IP stack with direct memory-to-memory messaging. Here the lower bandwidth requirements of the Scyld software can be served by a standard IP network, freeing the other network from any OS-related overhead completely.
It should be noted that these high performance interfaces may also run an IP stack, in which case they may also be used in the other configurations as well.
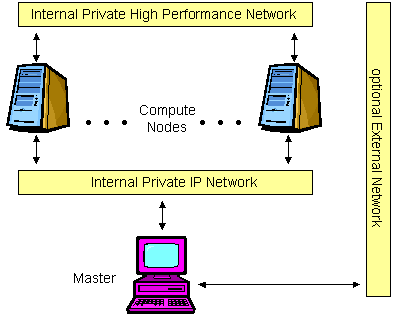
Figure 3. Performance Network Configuration
Server Network Configuration¶
The server network configuration is intended for web, database, or application servers. In this configuration, each compute node has multiple network interfaces, one for the private control network and one or more for the external public networks.
The Scyld ClusterWare security model is well-suited for this configuration. Even though
the compute nodes have a public network interface, there is no way to
log into them. There is no /etc/passwd file or other configuration
files to hack. There are no shells on the compute nodes to execute user
programs. The only open ports on the public network interface are the
ones your specific application opened.
To maintain this level of security, you may wish to have the master node on the internal private network only. The setup for this type of configuration is not described in this document, because it is very dependent on your target deployment. Contact Scyld’s technical support for help with a server network configuration.
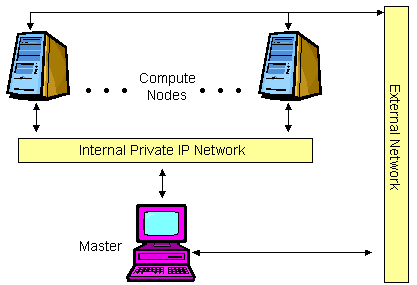
Figure 4. Server Network Configuration
System Data Flow¶
The following data flow diagram shows the primary messages sent over the private cluster network between the master node and compute nodes in a Scyld cluster. Data flows in three ways:
From the master node to the compute nodes
From the compute nodes to the master node
From the compute nodes to other compute nodes
The job control commands and cluster admin commands shown in the data flow diagram represent inputs to the master from users and administrators.
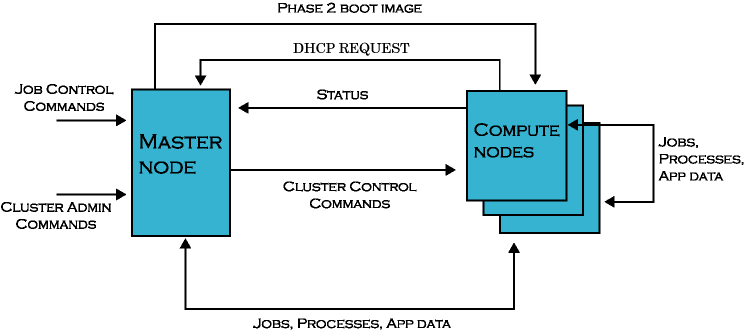
Figure 5. Scyld ClusterWare Data Flow Diagram
Master Node to Compute Node¶
Following is a list of the data items sent from the master node to a compute node, as depicted in the data flow diagram.
Cluster control commands — These are the commands sent from the master to the compute node telling it to perform such tasks as rebooting, halting, powering off, etc.
Files to be cached — The master node send the files to be cached on the compute nodes under Scyld JIT provisioning.
Jobs, processes, signals, and app data — These include the process snapshots captured by
Beowulffor migrating processes between nodes, as well as the application data sent between jobs.Beowulfis the collection of software that makes up Scyld, includingbeoservfor PXE/DHCP,BProc,beomap,beonss, andbeostat.Final boot images — The final boot image (formerly called the Phase 2 boot image) is sent from the master to a compute node in response to its Dynamic Host Configuration Protocol (DHCP) requests during its boot procedure.
Compute Node to Master Node¶
Following is a list of the data items sent from a compute node to the master node, as depicted in the data flow diagram.
DHCP and PXE requests — These requests are sent to the master from a compute node while it is booting. In response, the master replies back with the node’s IP address and the final boot image.
Jobs, processes, signals, and app data — These include the process snapshots captured by
Beowulffor migrating processes between nodes, as well as the application data sent between jobs.Performance metrics and node status — All the compute nodes in a Scyld cluster send periodic status information back to the master.
Compute Node to Compute Node¶
Following is a list of the data items sent between compute nodes, as depicted in the data flow diagram.
Jobs, processes, app data — These include the process snapshots captured by
Beowulffor migrating processes between nodes, as well as the application data sent between jobs.
System Software Context¶
The following diagram illustrates the software components available on the nodes in a Scyld cluster.
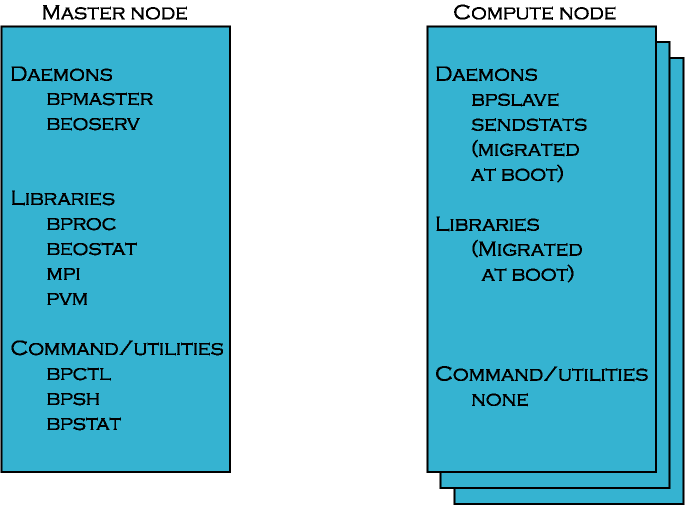
Figure 6. System Software Context Diagram
Master Node Software Components¶
The master node runs the bpmaster, beoserv, and recvstats
daemons. This node also stores the Scyld-specific libraries libbproc
and libbeostat, as well as Scyld-modified versions of utilities such
as MPICH, LAM, and PVM. The commands and utilities are a small subset of
all the software tools available on the master node.
Compute Node Software Components¶
The compute nodes run the beoclient daemon, which serves as the init
process on the compute nodes, and run the Scyld beoklogd,
bpslave, and sendstats daemons:
beoklogdis run as soon as the compute node establishes a network connection to the master node, ensuring that the master node begins capturing compute node kernel messages as early as possible.bpslaveis the compute node component ofBProc, and is necessary for supporting the unified process space and for migrating processes.sendstatsis necessary for monitoring the load on the compute node and for communicating the data to the master node’srecvstatsdaemon.kickbackproxycommunicates with the master node’skickbackdaemondaemon to retrieve Name Service (NSS) information from the master node, e.g., hostnames and user names.
In general, minimal binaries reside on compute nodes, thus minimizing
space consumed in a node’s RAM filesystem. By default, the directories
that contain common commands (e.g., /usr/bin) are NFS-mounted. User
applications are migrated from the master node to a compute node at
run-time, using a command such as bpsh, or are accessed using an NFS
mount. Libraries are pulled to a compute node on demand, as needed.
System Level Files¶
The following sections briefly describe the system level files found on the master node and compute nodes in a Scyld cluster.
Master Node Files¶
The file layout on the master node is the layout of the base Linux distribution. For those who are not familiar with the file layout that is commonly used by Linux distributions, here are some things to keep in mind:
/bin,/usr/bin— directories with user level command binaries/sbin,/usr/sbin— directories with administrator level command binaries/lib,/usr/lib— directories with static and shared libraries/usr/include— directory with include files/etc— directory with configuration files/var/log— directory with system log files/var/beowulf— directory with various ClusterWare image and status files/usr/share/doc— directory with various documentation files
Scyld ClusterWare also has some special directories and files on the master node that
are useful to know about. The per-node boot logs are stored in
/var/log/beowulf/node.N, where N is the node number. The
master node’s kernel and syslog messages are received by the syslog
or rsyslog service, which appends these log messages to the master’s
/var/log/messages file. By default, each compute node’s kernel and
syslog messages are forwarded to the master node’s logging service and
are also appended to the same /var/log/messages. However, the
compute node logging can be optionally forwarded to the syslog or
rsyslog service on another server. See the syslog_server= option
in Compute node command-line options for details.
The legacy behavior of the the compute node’s syslog handling has been
to introduce a date-time string to the message text, then forward the
message to the syslog server (typically on the master node), which would
add its own date-time string. This redundant timestamp violates the RFC
3164 format standard, and recent ClusterWare releases strips the compute
node’s timestamp before sending the text to the master server. If for
some reason a local cluster administrator wishes to revert to the
previous behavior, then edit the /etc/beowulf/config’s
kernelcommandline directive to add legacy_syslog=1.
Configuration files for Scyld ClusterWare are found in /etc/beowulf/. The directory
/usr/lib/beoboot/bin/ contains various scripts that are used to
configure compute nodes during boot, including the node_up and
setup_fs scripts.
For more information on the special directories, files, and scripts used by Scyld ClusterWare, see Special Directories, Configuration Files, and Scripts. Also see the Reference Guide.
Compute Node Files¶
Only a very few files exist on the compute nodes. For the most part, these files are all dynamic libraries; there are almost no actual binaries. For a detailed list of exactly what files exist on the compute nodes, see Special Directories, Configuration Files, and Scripts.
Technical Description¶
The following sections discuss some of the technical details of a Scyld
cluster, such as the compute node boot procedure, the BProc distributed
process space and Beowulf process migration software, compute node
categories and states, and miscellaneous components.
Compute Node Boot Procedure¶
The Scyld cluster architecture is designed around light-weight provisioning of compute nodes using the master node’s kernel and Linux distribution. Network booting ensures that what is provisioned to each compute node is properly version-synchronized across the cluster.
Earlier Scyld distributions supported a 2-phase boot sequence. Following
PXE boot of a node, a fixed Phase 1 kernel and initial RAM disk
(initrd) were copied to the node and installed. Alternatively, this
Phase 1 kernel and initrd were used to boot from local hard disk or
removable media. This Phase 1 boot package then built the node root
filesystem rootfs in RAM disk, requested the run-time (Phase 2)
kernel and used 2-Kernel-Monte to switch to it, then loaded the Scyld
daemons and initialized the BProc system. Means were provided for
installing the Phase 1 boot package on local hard disk and on removable
floppy and CD media.
Beginning with Scyld 30-series, PXE is the supported method for booting nodes into the cluster. For some years, all servers produced have supported PXE booting. For servers that cannot support PXE booting, Scyld ClusterWare provides the means to easily produce Etherboot media on CD to use as compute node boot media. ClusterWare can also be configured to boot a compute node from a local disk. See Special Directories, Configuration Files, and Scripts.
The Boot Package¶
The compute node boot package consists of the kernel, initrd, and
rootfs for each compute node. The beoboot command builds this
boot package.
By default, the kernel is the one currently running on the master node.
However, other kernels may be specified to the beoboot command and
recorded on a node-by-node basis in the Beowulf configuration file. This
file also includes the kernel command line parameters associated with
the boot package. This allows each compute node to potentially have a
unique kernel, initrd, rootfs, and kernel command lines.
Caution
Note that if you specify a different kernel to boot specific compute nodes, these nodes cannot be part of the
BProcunified process space.
The path to the initrd and rootfs are passed to the compute node
on the kernel command line, where it is accessible to the booting
software.
Each time the ClusterWare service restarts on the master node, the
beoboot command is executed to recreate the default compute node
boot package. This ensures that the package contains the same versions
of the components as are running on the master node.
Booting a Node¶
A compute node begins the boot process by sending a PXE request over the
cluster private network. This request is handled by the beoserv
daemon on the master node, which provides the compute node with an IP
address and (based on the contents of the Beowulf configuration file) a
kernel and initrd. If the cluster config file does not specify a
kernel and initrd for a particular node, then the defaults are used.
The cluster config file specifies the path to the kernel, the
initrd, and the rootfs. The initrd contains the minimal set
of programs for the compute node to establish a connection to the master
and request additional files. The rootfs is an archive of the root
filesystem, including the filesystem directory structure and certain
necessary files and programs, such as the bproc, filecache, and
task_packer kernel modules and bpslave daemon.
The beoserv daemon logs its dialog with the compute node, including
its MAC address, all of the node’s requests, and the responses. This
facilitates debugging of compute node booting problems.
The initrd and beoclient¶
Once the initrd is loaded, control is transferred to the kernel.
Within the Scyld architecture, booting is tightly controlled by the
compute node’s beoclient daemon, which also serves as the compute
node’s init process. The beoclient daemon uses configuration
files and executable binaries in the initrd and initial root filesystem
to load the the necessary kernel modules to establish the TCP/IP
connection back to the master node and basic access to local harddrives,
and starts various other daemons, such as beoklogd, which serves as
the node’s local system log server to forward kernel and syslog messages
(prefixed with the identify of the compute node) to the cluster’s syslog
server, and the bpslave daemon. Once beoclient has initialized
this basic BProc functionality, then the remaining boot sequence is
directed by and controlled by the master node through the node_up
and setup_fs scripts and various configuration files, bootstrapping
on top of the BProc functionality now executing on the node.
The beoklogd daemon normally forwards the kernel and syslog messages
from the compute node to the master node’s syslog or rsyslog
service. However, this compute node logging can be optionally directed
to an alternate server. See the syslog_server= option in
Compute node command-line options for details. To facilitate
debugging node booting problems, the kernel logging daemon on a compute
node is started as soon as the network driver is loaded and the network
connection to the syslog server is established.
The rootfs¶
Once the network connection to the master node is established and kernel
logging has been started, beoclient requests the rootfs archive,
using the path passed on the kernel command line. beoserv provides
the rootfs tarball, which is then uncompressed and expanded into a
RAM disk.
bpslave¶
The bpslave daemon establishes a connection to bpmaster on the
master node, and indicates that the compute node is ready to begin
accepting work. bpmaster then launches the node_up script, which
runs on the master node but completes initialization of the compute node
using the BProc commands (bpsh, bpcp, and bpctl).
BProc Distributed Process Space¶
Scyld Beowulf is able to provide a single system image through its use of
BProc, the Scyld process space management kernel enhancement. BProc
enables the processes running on cluster compute nodes to be visible and
manageable on the master node. Processes start on the master node and
are migrated to the appropriate compute node by BProc process migration
code. Process parent-child relationships and UNIX job control
information are maintained with the migrated jobs, as follows:
All processes appear in the master node’s process table.
All standard UNIX signals (kill, suspend, resume, etc.) can be sent to any process on a compute node from the master.
The stdin, stdout and stderr output from jobs is redirected back to the master through a socket.
BProc is one of the primary features that makes a Scyld cluster different
from a traditional Beowulf cluster. It is the key software component
that makes compute nodes appear as attached computational resources to
the master node. The figure below depicts the role BProc plays in a Scyld
cluster.
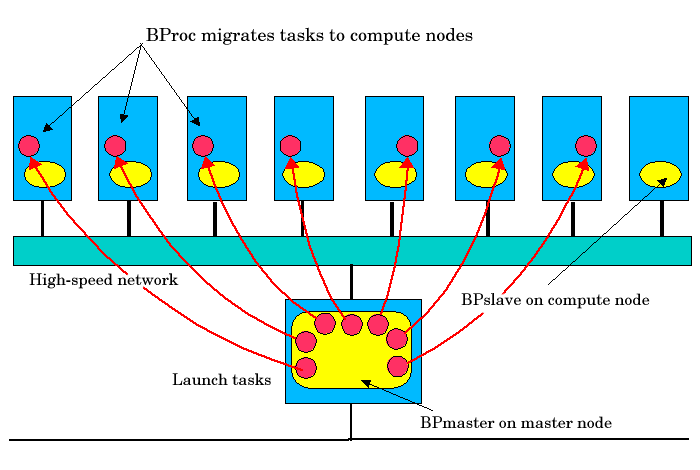
Figure 7. BProc Data Flows in a Scyld Cluster
BProc itself is divided into three components:
bpmaster— a daemon program that runs on the master node at all timesbpslave— a daemon program that runs on each of the compute nodeslibbproc— a library that provides a user programming interface to BProc runtime intrinsics.
The user of a Scyld cluster will never need to directly run or interact with these daemons. However, their presence greatly simplifies the task of running parallel jobs with Scyld ClusterWare.
The bpmaster daemon uses a process migration module (VMADump in
older Scyld systems or TaskPacker in newer Scyld systems) to freeze
a running process so that it can be transferred to a remote node. The
same module is also used by the bpslave daemon to thaw the process
after it has been received. In a nutshell, the process migration module
saves or restores a process’s memory space to or from a stream. In the
case of BProc, the stream is a TCP socket connected to the remote
machine.
VMADump and TaskPacker implement an optimization that greatly
reduces the size of the memory space required for storing a frozen
process. Most programs on the system are dynamically linked; at
run-time, they will use mmap to map copies of various libraries into
their memory spaces. Since these libraries are demand paged, the
entire library is always mapped even if most of it will never be used.
These regions must be included when copying a process’s memory space and
included again when the process is restored. This is expensive, since
the C library dwarfs most programs in size.
For example, the following is the memory space for the program
sleep. This is taken directly from /proc/pid/maps.
08048000-08049000 r-xp 00000000 03:01 288816 /bin/sleep
08049000-0804a000 rw-p 00000000 03:01 288816 /bin/sleep
40000000-40012000 r-xp 00000000 03:01 911381 /lib/ld-2.1.2.so
40012000-40013000 rw-p 00012000 03:01 911381 /lib/ld-2.1.2.so
40017000-40102000 r-xp 00000000 03:01 911434 /lib/libc-2.1.2.so
40102000-40106000 rw-p 000ea000 03:01 911434 /lib/libc-2.1.2.so
40106000-4010a000 rw-p 00000000 00:00 0
bfffe000-c0000000 rwxp fffff000 00:00 0
The total size of the memory space for this trivial program is 1,089,536
bytes; all but 32K of that comes from shared libraries. VMADump and
TaskPacker take advantage of this; instead of storing the data
contained in each of these regions, they store a reference to the
regions. When the image is restored, mmap will map the appropriate
files to the same memory locations.
In order for this optimization to work, VMADump and TaskPacker
must know which files to expect in the location where they are restored.
The bplib utility is used to manage a list of files presumed to be
present on remote systems.
Compute Node Categories¶
Each compute node in the cluster is classified into one of three categories by the master node: “configured”, “ignored”, or “unknown”. The classification of a node is dictated by whether or where it is listed in one of the following files:
The cluster config file
/etc/beowulf/config(includes both “configured” and “ignored nodes”)The unknown addresses file
/var/beowulf/unknown_addresses(includes “unknown” nodes only)
When a compute node completes its initial boot process, it begins to send out DHCP requests on all the network interface devices that it finds. When the master node receives a DHCP request from a new node, the new node will automatically be added to the cluster as “configured” until the maximum configured node count is reached. After that, new nodes will be classified as “ignored”. Nodes will be considered “unknown” only if the cluster isn’t configured to auto-insert or auto-append new nodes.
The cluster administrator can change the default node classification
behavi by manually editing the /etc/beowulf/config file (discussed
in Configuring the Cluster Manually). The classification of any
specific node can also be changed manually by the cluster administrator.
Also see Special Directories, Configuration Files, and Scripts to learn about special
directories, configuration files, and scripts.
Following are definitions of the node categories.
- Configured
A “configured” node is one that is listed in the cluster config file
/etc/beowulf/configusing the node tag. These are nodes that are formally part of the cluster, and are recognized as such by the master node. When running jobs on your cluster, the “configured” nodes are the ones actually used as computational resources by the master.- Ignored
An “ignored” node is one that is listed in the cluster config file
/etc/beowulf/configusing the ignore tag. These nodes are not considered part of the cluster, and will not receive the appropriate responses from the master during their boot process. New nodes that attempt to join the cluster after it has reached its maximum configured node count will be automatically classified as “ignored”.The cluster administrator can also classify a compute node as “ignored” if for any reason you’d like the master node to simply ignore that node. For example, you may choose to temporarily reclassify a node as “ignored” while performing hardware maintenance activities when the node may be rebooting frequently.
- Unknown
An “unknown” node is one not formally recognized by the cluster as being either “configured” or “ignored”. When the master node receives a DHCP request from a node not already listed as “configured” or “ignored” in the cluster configuration file, and the cluster is not configured to auto-insert or auto-append new nodes, it classifies the node as “unknown”. The node will be listed in the
/var/beowulf/unknown_addressesfile.
Compute Node States¶
Cluster compute nodes may be in any of several functional states, such
as down, up, or unavailable. Some of these states are transitional
(boot or shutdown); some are informational variants of the up
state (unavailable and error). BProc actually handles only 3 node
operational variations:
The node is not communicating — down. Variations of the down state may record the reason, such as halted (known to be halted by the master) or reboot (the master shut down the node with a reboot command).
The node is communicating — up, [up], alive, unavailable, or error. Here the strings indicate different levels of usability.
The node is transitioning — boot. This state has varying levels of communication, operating on scripted sequence.
During a normal power-on sequence, the user will see the node state
change from down to boot to up. Depending on the machine speed,
the boot phase may be very short and may not be visible due to the
update rate of the cluster monitoring tools. All state information is
reset to down whenever the bpmaster daemon is started/restarted.
In the following diagram, note that these states can also be reached via
imperative commands such as bpctl. This command can be used to put
the node into the error state, such as in response to an error
condition detected by a script.
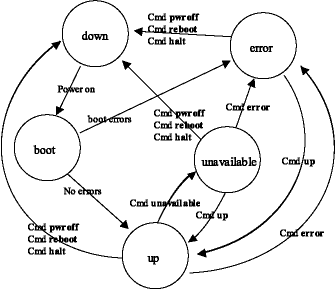
Figure 8. Node State Transition Diagram
Following are definitions of the compute node states:
downFrom the master node’s view, down means only that there is no communication with the compute node. A node is down when it is powered off, has been halted, has been rebooted, has a network link problem, or has some other hardware problem that prevents communication.
bootThis is a transitional state, during which the node will not accept user commands. The boot state is set when the
node_upscript has started and will transition to up or error when the script has completed. While in the boot state, the node will respond to administrator commands, but indicates that the node is still being configured for normal operation. The duration of this state varies with the complexity of thenode_upscript.upThis is a functional state, set when the
node_upscript has completed without encountering any errors.BProcchecks the return status of the script and sets the node state to up if the script was successful. This is the only state where the node is available to non-administrative users, asBProcchecks this before moving any program to a node; administrator programs bypass this check. This state may also be commanded when the previous state was unavailable or error.errorThis is an informational state, set when the
node_upscript has exited with errors. The administrator may access the node, or look in the/var/log/beowulf/node.x (where x is a node number) file to determine the problem. If a problem is seen to be non-critical, the administrator may then set the node to up.unavailableThis is a functional state. The node is not available for non-administrative users; however, it is completely available to the administrator. Currently running jobs will not be affected by a transition to this state. With respect to job control, this state comes into play only when attempting to run new jobs, as new jobs will fail to migrate to a node marked unavailable. This state is intended to allow node maintenance without having to bring the node offline.
[up]This Scyld ClusterWare node is up and is being actively managed by another master node, which for now is the node’s primary master. The secondary master node(s) see the node as [up]. A secondary master can ssh to the node (if ssh is enabled), but the node only responds to
BProccommands from its primary master (e.g.,bpshandbpcp). See Managing Multiple Master Nodes for details.aliveThis non-Scyld node is alive to the extent that it is running the
sendstatsdaemon to report various/procstatistics about the node state, and it is integrated as a compute node in the cluster. For example, the Job Manager may be able to run jobs on this node. See Managing Non-Scyld Nodes for details.
Miscellaneous Components¶
Scyld ClusterWare includes several miscellaneous components, such as name lookup
functionality (beonss), IP communications ports, library caching,
and external data access.
beonss¶
beonss provides name service lookup functionality for Scyld ClusterWare. The
information it provides includes hostnames, netgroups, and user
information. In general, whatever name service information is available
to the master node, using whatever query methods available to the master
node (e.g., NIS, LDAP), is also transparently available to the compute
nodes through the beonss functionality. The Scyld ClusterWare installation
automatically (and silently) configures beonss.
Hostnamesbeonssprovides dynamically generated hostnames for all the nodes in the cluster. The hostnames are of the form .<nodenumber>, so the hostname for node 0 would be .0, the hostname for node 50 would be .50, and the hostname for the master node would be .-1.The nodename entries in the
/etc/beowulf/configfile allow for the declaration of additional hostname aliases for compute nodes. For instance,nodename n%N
declares aliases for nodes, e.g., n4 is an alias for node .4. For another example, suppose the IP address of node 4 is 10.0.0.4, and suppose that node 4 has its IPMI interface configured to respond to the IP address 10.1.0.4. Then the line:
nodename n%N-ipmi 0.1.0.0 ipmi
declares aliases for the hostnames in the group called ipmi. The hostname n4-ipmi is the arithmetic sum of n4’s IP address 10.1.0.4 plus the offset 0.1.0.0, forming the IP address 10.1.0.4. See
man beowulf-configand the comments in the file/etc/beowulf/configfor details and other examples.beonssalso provides the hostname master, which always points to the IP of the master node on the cluster’s internal network. The hostnames .-1 and master always point to the same IP.These hostnames will always point to the right IP address based on the configuration of your IP range. You don’t need to do anything special for these hostnames to work. Also, these hostnames will work on the master node or any of the compute nodes.
Note that
beonssdoes not know the hostname and IP address that the master node uses for the outside network. Suppose your master node has the public name mycluster and uses the IP address 1.2.3.4 for the outside network. By default, a compute node on the private network will be unable to open a connection to mycluster or to 1.2.3.4. However, by enabling IP forwarding in both the/etc/beowulf/configfile and the/etc/sysctl.conffile, compute nodes can resolve hostnames and access hosts that are accessible by the master through the master’s public network interface, provided you have your DNS services working and available on the compute nodes.Tip
When you enable IP forwarding, the master node will set up NAT routing between your compute nodes and the outside world, so your compute nodes will be able to make outbound connections. However, this does not enable outsiders to access or “see” your compute nodes.
Caution
On compute nodes the NFS directories must be mounted using either the NFS server’s IP address or the “$MASTER” keyword, as is specified in the
/etc/beowulf/fstabfile. Hostnames cannot be used because the compute node’s NFS mounting is performed before the node’s name service is active, which would otherwise be able to translate a hostname to its IP address.NetgroupsNetgroups are a concept from NIS. They make it easy to specify an arbitrary list of machines, then treat all those machines the same when carrying out an administrative procedure (for example, specifying what machines to export NFS filesystems to).
beonsscreates one netgroup called cluster, which includes all of the nodes in the cluster. This is used in the default/etc/exportsfile in order to easily export/hometo all of the compute nodes.User InformationWhen jobs are running on the compute nodes,
beonssallows the standardgetpwnam()andgetpwuid()functions to successfully retrieve information (such as username, home directory, shell, and uid), as long as these functions are retrieving information on the user that is running the program. All other information thatgetpwnam()andgetpwuid()would normally retrieve will be set to “NULL”.
IP Communications Ports¶
Scyld ClusterWare uses a few TCP/IP and UDP/IP communication ports when sending information between nodes. Normally, this should be completely transparent to the user. However, if the cluster is using a switch that blocks various ports, it may be important to know which ports are being used and for what.
Following are key components of Scyld ClusterWare and the ports they use:
beoserv— This daemon is responsible for replying to the DHCP request from a compute node when it is booting. The reply includes a new kernel, the kernel command line options, and a small final boot RAM disk. The daemon supports both multi-cast and uni-cast file serving.By default,
beoservuses TCP port 932. This can be overridden by changing the value of the server beofs2 directive (formerly server tcp, which is deprecated but continues to be accepted) in the/etc/beowulf/configfile to the desired port number.BProc— This ClusterWare component provides unified process space, process migration, and remote execution of commands on compute nodes. By default,BProcuses TCP port 933. This can be overridden by changing the value of the server bproc directive in the/etc/beowulf/configfile to the desired port number.BeoStat— This service is composed of compute node daemons (sendstats), a master node daemon (recvstats), and a master node library (libbeostat) that collects performance metrics and status information from compute nodes and transmits this information to the master node for cacheing and for distribution to the various cluster monitoring display tools. The daemons use UDP port 5545 by default.
Library Caching¶
One of the features Scyld ClusterWare uses to improve the performance of transferring
jobs to and from compute nodes is to cache libraries. When BProc needs to
migrate a job between nodes, it uses the process migration code
(VMADump or TaskPacker) to take a snapshot of all the memory the
process is using, including the binary and shared libraries. This memory
snapshot is then sent across the private cluster network during process
migration.
VMADump and TaskPacker take advantage of the fact that libraries
are being cached on the compute nodes. The shared library data is not
included in the snapshot, which reduces the amount of information that
needs to be sent during process migration. By not sending over the
libraries with each process, Scyld ClusterWare is able to reduce network traffic, thus
speeding up cluster operations.
External Data Access¶
There are several common ways for processes running on a compute node to access data stored externally to the cluster, as discussed below.
Transfer the data.
You can transfer the data to the master node using a protocol such as
scp or ftp, then treat it as any other file that resides on the
master node.
Access the data through a network filesystem, such as NFS or AFS. Any remote filesystem mounted on the master node can’t be re-exported to the compute node. Therefore, you need to use another method to access the data on the compute nodes. There are two options:
Use
bpshto start your job, and use shell redirection on the master node to send the data asstdinfor the jobUse MPI and have the rank 0 job read the data, then use MPI’s message passing capabilities to send the data.
If you have a job that is natively using Beowulf functions, you can also
have your job read the data on the master node before it moves itself to
the compute nodes.
NFS mount directories from external file servers. There are two options:
For file servers directly connected to the cluster private network, this can be done directly, using the file server’s IP address. Note that the server name cannot be used, because the name service is not yet up when
/etc/beowulf/fstabis evaluated.For file servers external to the cluster, setting up IP forwarding on the master node allows the compute nodes to mount exported directories using the file server’s IP address.
Use a cluster filesystem. If you have questions regarding the use of any particular cluster filesystem with Scyld ClusterWare, contact Scyld Customer Support for assistance.
Software Components¶
The following sections describe the various software packages in Scyld ClusterWare, along with their individual components. For additional information, see the Reference Guide.
BeoBoot Tools¶
The following tools are associated with the beoboot package. For
additional information, see the Reference Guide.
BeoBootThis utility is used to generate boot images for the compute nodes in the cluster. Earlier versions of Scyld used two types of images, initial (Phase 1) and final (Phase 2). The initial images were placed on the hard disk or a floppy disk, and were used to boot the nodes. The final image was downloaded from the master node by the initial image. Currently, only the final image is used by Scyld ClusterWare; support for initial images has been dropped.
By default, the final image is stored on the master node in the
/var/beowulf/boot.imgfile; this is where thebeoservdaemon expects to find it. Where initial images were used to begin the network boot process for systems that lacked PXE support, Scyld now provides PXELinux for this purpose. Bootable PXELinux media may be created for CD-ROM booting.beoservThis is the
BeoBootdaemon. It responds to DHCP requests from the compute nodes in the cluster and serves them their final boot images over the private cluster network.
BProc Daemons¶
The following daemons are associated with BProc. For additional
information, see the Reference Guide.
bpmasterThis is the
BProcmaster daemon. It runs on the master node, listening on a TCP port and accepting connections frombpslavedaemons. Configuration information comes from the/etc/beowulf/configfile.bpslaveThis is the
BProccompute daemon. It runs on a compute node to accept jobs from the master, and connects to the master through a TCP port.
BProc Clients¶
The following command line utilities are closely related to BProc. For
additional information, see the Reference Guide.
bpshThis is a replacement for
rsh(remote shell). It runs a specified command on an individually referenced node. The “nodenum” parameter may be a single node number, a comma delimited list of nodes, “-a” for all nodes that are up, or “-A” for all nodes that are not down.bpshwill forward standard input, standard output, and standard error for the remote processes it spawns. Standard output and error are forwarded subject to specified options; standard input will be forwarded to the remote processes. If there is more than one remote process, standard input will be duplicated for every remote node. For a single remote process, the exit status ofbpshwill be the exit status of the remote process.bpctlThis is the
BProccontrol utility. It can be used to apply various commands to individually referenced nodes.bpctlcan be used to change the user and group ownership settings for a node; it can also be used to set a node’s state. Finally, this utility can be used to query such information as the node’s IP address.bpcpThis utility can be used to copy files between machines in the cluster. Each file (f1…fn) or directory argument (dir) is either a remote file name of the form node:path, or a local file name (containing no colon “:” characters).
bpstatThis command displays various pieces of status information about the compute nodes. The display is formatted in columns specifying node number, node status, node permission, user access, and group access. This program also includes a number of options intended to be useful for scripts.
ClusterWare Utilities¶
Following are various command line and graphical user interface (GUI) utilities that are part of Scyld ClusterWare. For additional information, see the Reference Guide.
beostatThe
beostatcommand line tool is a text-based utility used to monitor cluster status and performance. This tool provides a text listing of the information from the/procstructure on each node. See Monitoring the Status of the Cluster for a discussion of this tool.beostatusThe
beostatusGUI tool is used to monitor cluster status and performance. See Monitoring the Status of the Cluster for a discussion of this tool.