Scyld ClusterWare Overview¶
Scyld ClusterWare is a Linux-based high-performance computing system. It solves many of the problems long associated with Linux Beowulf-class cluster computing, while simultaneously reducing the costs of system installation, administration, and maintenance. With Scyld ClusterWare, the cluster is presented to the user as a single, large-scale parallel computer.
This chapter presents a high-level overview of Scyld ClusterWare. It begins with a brief history of Beowulf clusters, and discusses the differences between the first-generation Beowulf clusters and a Scyld cluster. A high-level technical summary of Scyld ClusterWare is then presented, covering the top-level features and major software components of Scyld. Finally, typical applications of Scyld ClusterWare are discussed.
Additional details are provided throughout the Scyld ClusterWare documentation set.
What Is a Beowulf Cluster?¶
The term “Beowulf” refers to a multi-computer architecture designed for executing parallel computations. A “Beowulf cluster” is a parallel computer system conforming to the Beowulf architecture, which consists of a collection of commodity off-the-shelf computers (COTS) (referred to as “nodes”), connected via a private network running an open-source operating system. Each node, typically running Linux, has its own processor(s), memory storage, and I/O interfaces. The nodes communicate with each other through a private network, such as Ethernet or Infiniband, using standard network adapters. The nodes usually do not contain any custom hardware components, and are trivially reproducible.
One of these nodes, designated as the “master node”, is usually attached to both the private and public networks, and is the cluster’s administration console. The remaining nodes are commonly referred to as “compute nodes”. The master node is responsible for controlling the entire cluster and for serving parallel jobs and their required files to the compute nodes. In most cases, the compute nodes are configured and controlled by the master node. Typically, the compute nodes require neither keyboards nor monitors; they are accessed solely through the master node. From the viewpoint of the master node, the compute nodes are simply additional processor and memory resources.
In conclusion, Beowulf is a technology of networking Linux computers together to create a parallel, virtual supercomputer. The collection as a whole is known as a “Beowulf cluster”. While early Linux-based Beowulf clusters provided a cost-effective hardware alternative to the supercomputers of the day, allowing users to execute high-performance computing applications, the original software implementations were not without their problems. Scyld ClusterWare addresses — and solves — many of these problems.
A Brief History of the Beowulf¶
Cluster computer architectures have a long history. The early network-of-workstations (NOW) architecture used a group of standalone processors connected through a typical office network, their idle cycles harnessed by a small piece of special software, as shown below.
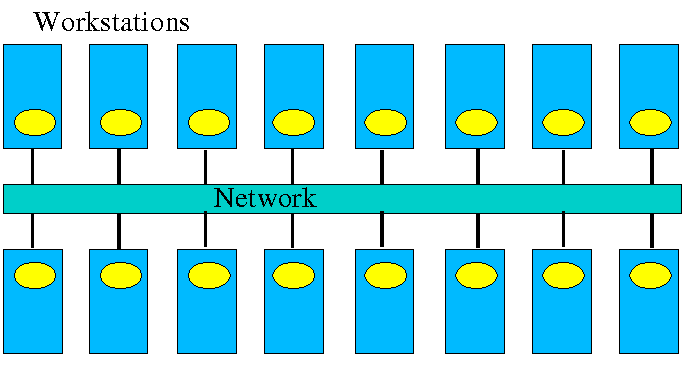
Figure 1. Network-of-Workstations Architecture
The NOW concept evolved to the Pile-of-PCs architecture, with one master PC connected to the public network, and the remaining PCs in the cluster connected to each other and to the master through a private network as shown in the following figure. Over time, this concept solidified into the Beowulf architecture.
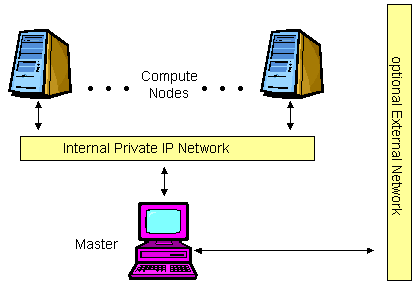
Figure 2. A Basic Beowulf Cluster
For a cluster to be properly termed a “Beowulf”, it must adhere to the “Beowulf philosophy”, which requires:
Scalable performance
The use of commodity off-the-shelf (COTS) hardware
The use of an open-source operating system, typically Linux
Use of commodity hardware allows Beowulf clusters to take advantage of the economies of scale in the larger computing markets. In this way, Beowulf clusters can always take advantage of the fastest processors developed for high-end workstations, the fastest networks developed for backbone network providers, and so on. The progress of Beowulf clustering technology is not governed by any one company’s development decisions, resources, or schedule.
First-Generation Beowulf Clusters¶
The original Beowulf software environments were implemented as downloadable add-ons to commercially-available Linux distributions. These distributions included all of the software needed for a networked workstation: the kernel, various utilities, and many add-on packages. The downloadable Beowulf add-ons included several programming environments and development libraries as individually-installable packages.
With this first-generation Beowulf scheme, every node in the cluster required a full Linux installation and was responsible for running its own copy of the kernel. This requirement created many administrative headaches for the maintainers of Beowulf-class clusters. For this reason, early Beowulf systems tended to be deployed by the software application developers themselves (and required detailed knowledge to install and use). Scyld ClusterWare reduces and/or eliminates these and other problems associated with the original Beowulf-class clusters.
Scyld ClusterWare: A New Generation of Beowulf¶
Scyld ClusterWare streamlines the process of configuring, administering, running, and maintaining a Beowulf-class cluster computer. It was developed with the goal of providing the software infrastructure for commercial production cluster solutions.
Scyld ClusterWare was designed with the differences between master and compute nodes in mind; it runs only the appropriate software components on each compute node. Instead of having a collection of computers each running its own fully-installed operating system, Scyld creates one large distributed computer. The user of a Scyld cluster will never log into one of the compute nodes nor worry about which compute node is which. To the user, the master node is the computer, and the compute nodes appear merely as attached processors capable of providing computing resources.
With Scyld ClusterWare, the cluster appears to the user as a single computer. Specifically,
The compute nodes appear as attached processor and memory resources
All jobs start on the master node, and are migrated to the compute nodes at runtime
All compute nodes are managed and administered collectively via the master node
The Scyld ClusterWare architecture simplifies cluster setup and node integration, requires minimal system administration, provides tools for easy administration where necessary, and increases cluster reliability through seamless scalability. In addition to its technical advances, Scyld ClusterWare provides a standard, stable, commercially-supported platform for deploying advanced clustering systems. See the next section for a technical summary of Scyld ClusterWare.
Scyld ClusterWare Technical Summary¶
Scyld ClusterWare presents a more uniform system view of the entire cluster to both users and applications through extensions to the kernel. A guiding principle of these extensions is to have little increase in both kernel size and complexity and, more importantly, negligible impact on individual processor performance.
In addition to its enhanced Linux kernel, Scyld ClusterWare includes libraries and utilities specifically improved for high-performance computing applications. For information on the Scyld libraries, see the Reference Guide. Information on using the Scyld utilities to run and monitor jobs is provided in Interacting With the System and Running Programs. If you need to use the Scyld utilities to configure and administer your cluster, see the Administrator’s Guide.
Top-Level Features of Scyld ClusterWare¶
The following list summarizes the top-level features of Scyld ClusterWare.
Security and Authentication. With Scyld ClusterWare, the master node is a single point of security administration and authentication. The authentication envelope is drawn around the entire cluster and its private network. This obviates the need to manage copies or caches of credentials on compute nodes or to add the overhead of networked authentication. Scyld ClusterWare provides simple permissions on compute nodes, similar to Unix file permissions, allowing their use to be administered without additional overhead.
Easy Installation. Scyld ClusterWare is designed to augment a full Linux distribution, such as Red Hat Enterprise Linux (RHEL) or CentOS. The installer used to initiate the installation on the master node is provided on an auto-run CD-ROM. You can install from scratch and have a running Linux HPC cluster in less than an hour. See the Installation Guide for full details.
Install Once, Execute Everywhere. A full installation of Scyld ClusterWare is required only on the master node. Compute nodes are provisioned from the master node during their boot process, and they dynamically cache any additional parts of the system during process migration or at first reference.
Single System Image. Scyld ClusterWare makes a cluster appear as a multi-processor parallel computer. The master node maintains (and presents to the user) a single process space for the entire cluster, known as the BProc Distributed Process Space. BProc is described briefly later in this chapter, and more details are provided in the Administrator’s Guide.
Execution Time Process Migration. Scyld ClusterWare stores applications on the master node. At execution time, BProc migrates processes from the master to the compute nodes. This approach virtually eliminates both the risk of version skew and the need for hard disks on the compute nodes. More information is provided in the section on process space migration later in this chapter. Also refer to the BProc discussion in the Administrator’s Guide.
Seamless Cluster Scalability. Scyld ClusterWare seamlessly supports the dynamic addition and deletion of compute nodes without modification to existing source code or configuration files.
Administration Tools. Scyld ClusterWare includes simplified tools for performing cluster administration and maintenance. Both graphical user interface (GUI) and command line interface (CLI) tools are supplied. See the Administrator’s Guide for more information.
Web-Based Administration Tools. Scyld ClusterWare includes web-based tools for remote administration, job execution, and monitoring of the cluster. See the Administrator’s Guide for more information.
Additional Features. Additional features of Scyld ClusterWare include support for cluster power management (IPMI and Wake-on-LAN, easily extensible to other out-of-band management protocols); runtime and development support for MPI and PVM; and support for the LFS and NFS3 file systems.
Fully-Supported. Scyld ClusterWare is fully-supported by Penguin Computing, Inc.
Process Space Migration Technology¶
Scyld ClusterWare is able to provide a single system image through its use of the BProc
Distributed Process Space, the Beowulf process space management kernel
enhancement. BProc enables the processes running on compute nodes to be
visible and managed on the master node. All processes appear in the master
node’s process table, from which they are migrated to the appropriate compute
node by BProc. Both process parent-child relationships and Unix
job-control information are maintained with the migrated jobs. The
stdout and stderr streams are redirected to the user’s ssh
or terminal session on the master node across the network.
The BPorc mechanism is one of the primary features that makes Scyld ClusterWare different from traditional Beowulf clusters. For more information, see the system design description in the Administrator’s Guide.
Compute Node Provisioning¶
Scyld ClusterWare utilizes light-weight provisioning of compute nodes from the master node’s kernel and Linux distribution. For Scyld Series 30 and Scyld ClusterWare, PXE is the supported method for booting nodes into the cluster; the 2-phase boot sequence of earlier Scyld distributions is no longer used.
The master node is the DHCP server serving the cluster private network.
PXE booting across the private network ensures that the compute node
boot package is version-synchronized for all nodes within the cluster.
This boot package consists of the kernel, initrd, and rootfs. If
desired, the boot package can be customized per node in the Beowulf
configuration file /etc/beowulf/config, which also includes the
kernel command line parameters for the boot package.
For a detailed description of the compute node boot procedure, see the system design description in the Administrator’s Guide. Also refer to the chapter on compute node boot options in that document.
Compute Node Categories¶
Compute nodes seen by the master over the private network are classified into one of three categories by the master node, as follows:
Unknown — A node not formally recognized by the cluster as being either a Configured or Ignored node. When bringing a new compute node online, or after replacing an existing node’s network interface card, the node will be classified as unknown.
Ignored — Nodes which, for one reason or another, you’d like the master node to ignore. These are not considered part of the cluster, nor will they receive a response from the master node during their boot process.
Configured — Those nodes listed in the cluster configuration file using the “node” tag. These are formally part of the cluster, recognized as such by the master node, and used as computational resources by the cluster.
For more information on compute node categories, see the system design description in the Administrator’s Guide.
Compute Node States¶
BProc maintains the current condition or “node state” of each configured compute node in the cluster. The compute node states are defined as follows:
down — Not communicating with the master, and its previous state was either down, up, error, unavailable, or boot.
unavailable — Node has been marked unavailable or “off-line” by the cluster administrator; typically used when performing maintenance activities. The node is useable only by the user root.
error — Node encountered an error during its initialization; this state may also be set manually by the cluster administrator. The node is useable only by the user root.
up — Node completed its initialization without error; node is online and operating normally. This is the only state in which non-root users may access the node.
reboot — Node has been commanded to reboot itself; node will remain in this state until it reaches the boot state, as described below.
halt — Node has been commanded to halt itself; node will remain in this state until it is reset (or powered back on) and reaches the boot state, as described below.
pwroff — Node has been commanded to power itself off; node will remain in this state until it is powered back on and reaches the boot state, as described below.
boot — Node has completed its stage 2 boot but is still initializing. After the node finishes booting, its next state will be either up or error.
For more information on compute node states, see the system design description in the Administrator’s Guide.
Major Software Components¶
The following is a list of the major software components included with Scyld ClusterWare. For more information, see the relevant sections of the Scyld ClusterWare documentation set, including the Installation Guide, Administrator’s Guide, User’s Guide, Reference Guide, and Programmer’s Guide.
BProc— The process migration technology; an integral part of Scyld ClusterWare.BeoSetup— A GUI for configuring the cluster.BeoStatus— A GUI for monitoring cluster status.beostat— A text-based tool for monitoring cluster status.beoboot— A set of utilities for booting the compute nodes.beofdisk— A utility for remote partitioning of hard disks on the compute nodes.beoserv— The cluster’s DHCP, PXE and dynamic provisioning server; it responds to compute nodes and serves the boot image.BPmaster— TheBProcmaster daemon; it runs on the master node.BPslave— TheBProccompute daemon; it runs on each of the compute nodes.bpstat— ABProcutility that reports status information for all nodes in the cluster.bpctl— ABProccommand line interface for controlling the nodes.bpsh— ABProcutility intended as a replacement forrsh(remote shell).bpcp— ABProcutility for copying files between nodes, similar torcp(remote copy).MPI— The Message Passing Interface, optimized for use with Scyld ClusterWare.PVM— The Parallel Virtual Machine, optimized for use with Scyld ClusterWare.mpprun— A parallel job-creation package for Scyld ClusterWare.
Typical Applications of Scyld ClusterWare¶
Scyld clustering provides a facile solution for anyone executing jobs that involve either a large number of computations or large amounts of data (or both). It is ideal for both large, monolithic, parallel jobs and for many normal-sized jobs run many times (such as Monte Carlo type analysis).
The increased computational resource needs of modern applications are frequently being met by Scyld clusters in a number of domains, including:
Computationally-Intensive Activities — Optimization problems, stock trend analysis, financial analysis, complex pattern matching, medical research, genetics research, image rendering
Scientific Computing / Research — Engineering simulations, 3D-modeling, finite element analysis, computational fluid dynamics, computational drug development, seismic data analysis, PCB / ASIC routing
Large-Scale Data Processing — Data mining, complex data searches and results generation, manipulating large amounts of data, data archival and sorting
Web / Internet Uses — Web farms, application serving, transaction serving, data serving
These types of jobs can be performed many times faster on a Scyld cluster than on a single computer. Increased speed depends on the application code, the number of nodes in the cluster, and the type of equipment used in the cluster. All of these can be easily tailored and optimized to suit the needs of your applications.