Cluster Architecture Overview¶
A minimal ClusterWare cluster consists of a head node and one or more compute nodes, all interconnected via a private cluster network. User applications generally execute on the compute nodes, are often multithreaded across multiple compute nodes, and are usually coordinated by a job scheduler.
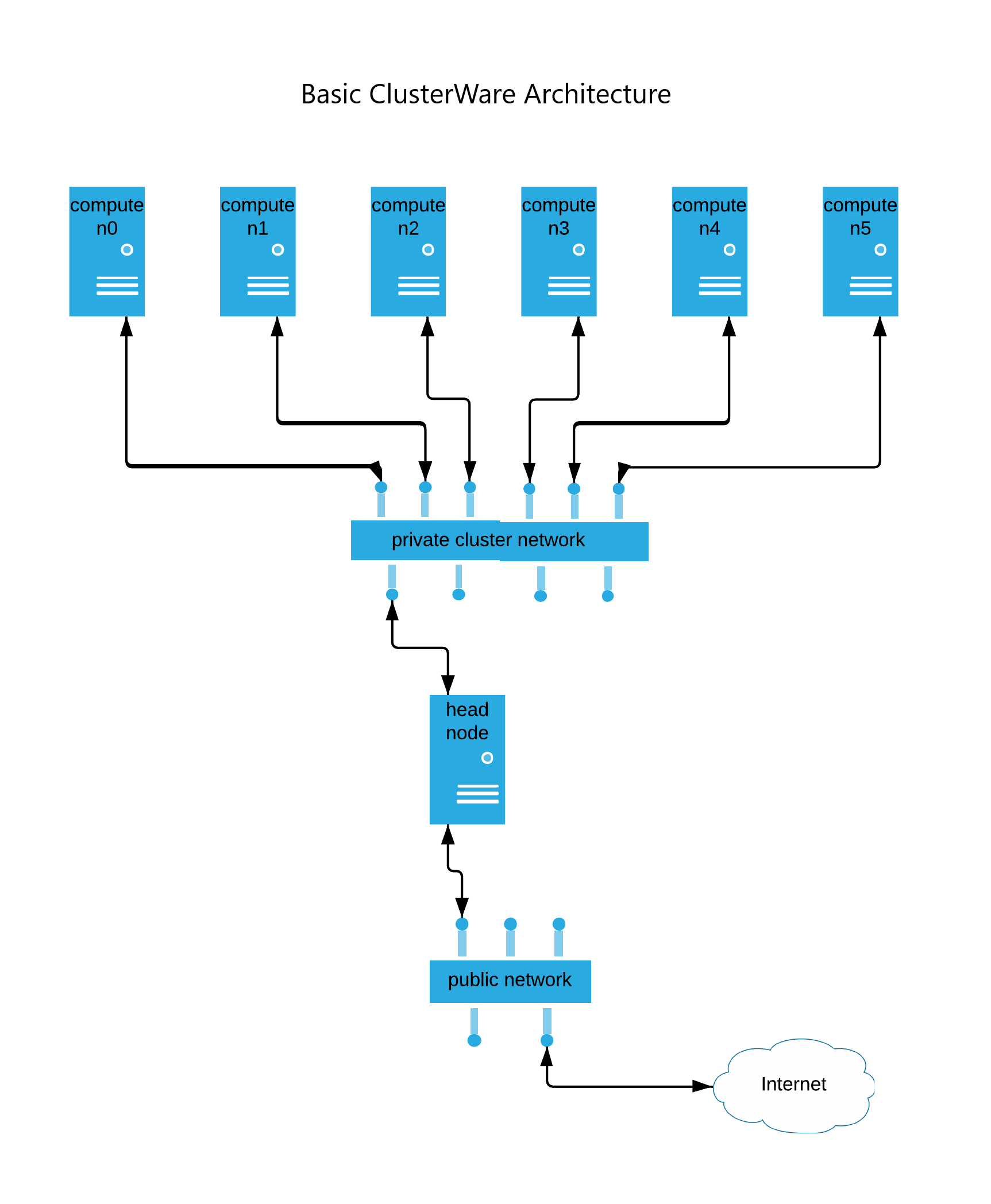
The head node is responsible for provisioning compute nodes, beginning with responding to a compute node's DHCP request for an IP address, and then (depending upon the compute node's BIOS settings) the compute node either boots from its local storage, or the compute node makes PXEboot requests for the kernel, initrd, and root filesystem images.
A ClusterWare head node usually also functions as a server for:
The distributed Key/Value Database is implemented by the ClusterWare database and is accessed through the REST API via command line or graphical tools. It is the repository for information such as:
The MAC address to IP address and node number mappings.
The locations of the storage for the kernel, initrd, and root filesystem PXEboot images.
Compute node attributes, basic hardware and status, and configuration details.
The storage for the images themselves.
The compute node status information, which can be visualized by shell commands or by graphical tools. This is implemented by default by Telegraf, InfluxDB version 2, and Grafana and its Performance Co-Pilot plugin.
Optional network storage, e.g., an NFS server.
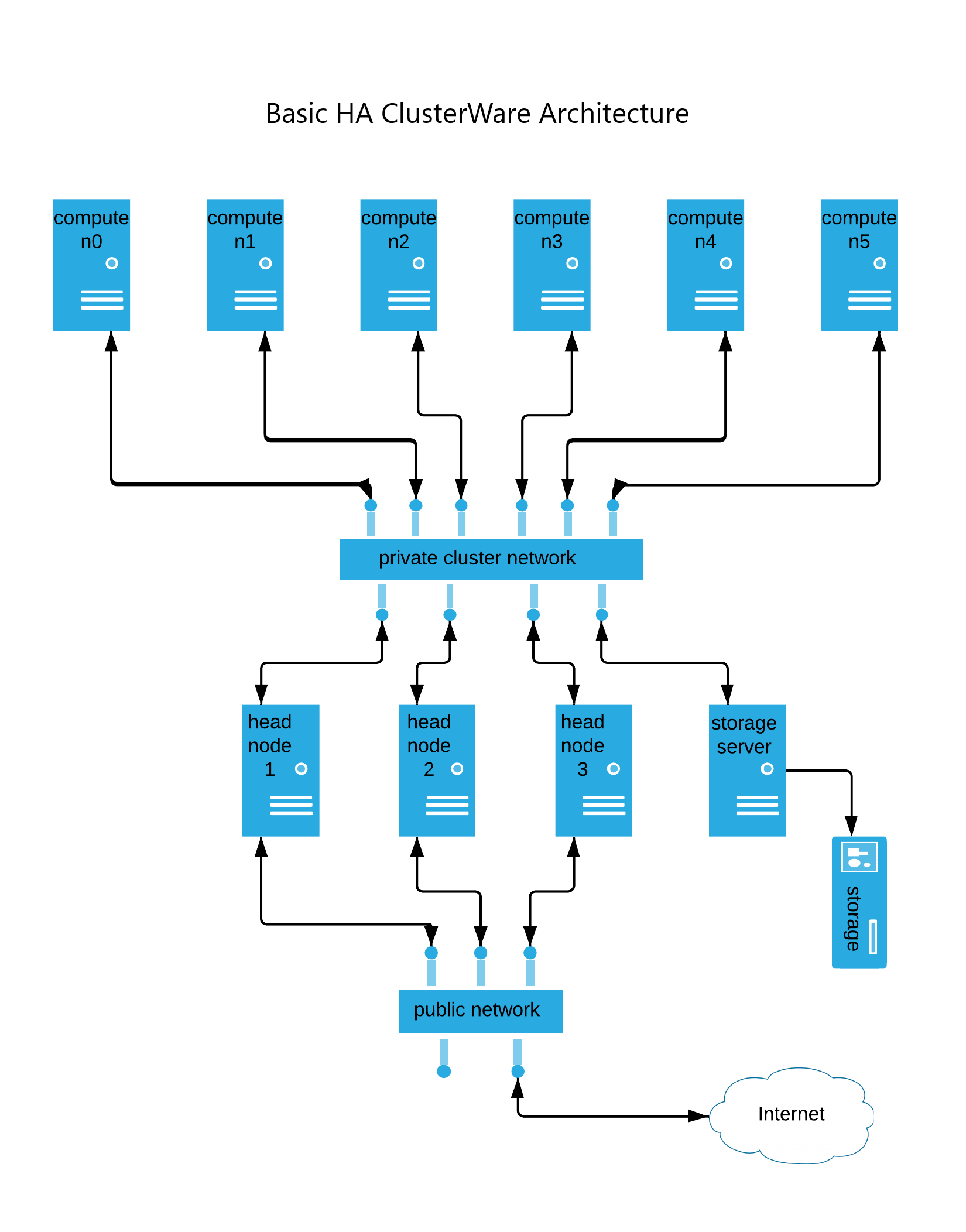
A more complex cluster can be High Availability (HA), consisting of multiple head nodes where each head node has access to the distributed database and shared image storage. In an active-active(-active....) relationship, each head node can manage any compute node, providing it with boot files and forwarding its status information into the shared database. Since no particular head node is specifically necessary to manage an individual compute node, then any head node can take over responsibility for the compute nodes that were previously communicating with a now-failed head node.
Note
Some network protocols, e.g. iSCSI, do not easily handle this sort of handoff, and any clusters using these protocols may experience additional difficulties on head node failure.
A complex cluster can also employ separate servers for the network storage, the compute node status information, and the boot images storage. For example:
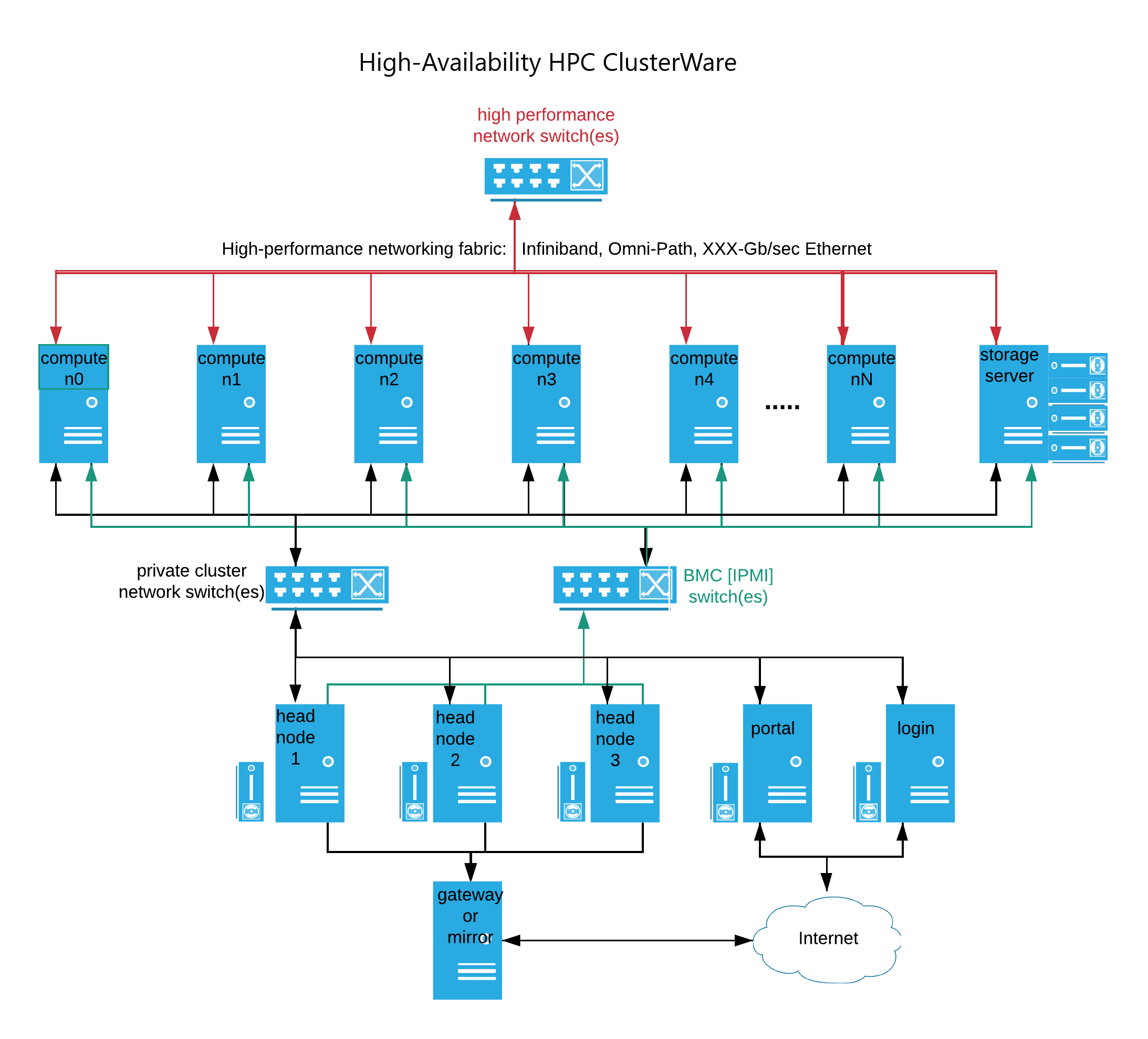
An even more complex cluster may employ high-performance networking, such as Infiniband, Omni-Path, or even 40GB/sec or faster Ethernet, in addition to the typical 1Gb/sec or 10Gb/sec Ethernet that commonly interconnects nodes on the private cluster network. This faster (and more expensive) network fabric typically interconnects the compute nodes and commonly also shared cluster-wide storage.
The head node(s) commonly also have IPMI access to each compute node's Base Management Controller (BMC), which provides for command-line or programmatic access to the compute nodes at a more basic hardware level, allowing for remote control of power, forcing a reboot, viewing hardware state, and more.
Also common is the use of Scyld Cloud Manager (SCM) to manage user access and accounting. User administrators (distinguished from cluster administrators, who have sudo-access to powerful ClusterWare tools) connect to the cluster portal to create virtual login node(s). Cluster users ssh to login nodes to build or install applications, download data into the cluster's data storage, submit jobs to a job scheduler for execution on compute nodes, and upload results back to the user's home system.
Some complex clusters connect head nodes to the public Internet via a gateway, e.g., to allow a cluster administrator to use yum to install or update software from Internet-accessible websites. Other complex clusters provide no head node access to the Internet and keep software hosted on a cluster-internal mirror server, where the local cluster administrator has precise control over updates.
For example:
Scyld ClusterWare Software Overview¶
A Scyld ClusterWare head node expects to execute in a Red Hat RHEL or CentOS 7.6 to 8.4, Oracle Linux 7.9 to 8.4, or Rocky 8.4 environment.
Visit https://docs.redhat.com/docs/en-US/Red_Hat_Enterprise_Linux to view the Red Hat Enterprise Linux RHEL7 Release Notes and other useful documents, including the Migration Planning Guide and System Administrator's Guide.
ClusterWare provides the tools (commonly named with prefix scyld-)
and services (e.g., the key-value database) for a cluster administrator
to install, administer, and monitor a Beowulf-style cluster.
A cluster administrator commonly employs a shell on a head node to perform
these functions.
ClusterWare additionally distributes packages for an administrator to install
an optional job manager (e.g., Slurm, OpenPBS, TORQUE), Kubernetes,
and several varieties of OpenMPI-family software stacks for user applications.
The Installation & Administrator Guide describes this with much greater detail.
The ClusterWare Database¶
The ClusterWare database is stored as JSON content within a replicated document store distributed among the ClusterWare head nodes. This structure protects against the failure of any single head node.
ClusterWare originally employed the community edition of either Couchbase or etcd as its distributed database, using a layer of pluggable database-specific modules between the user interface (command-line or graphical) and the database that allowed for switching between those different database types. ClusterWare now only supports etcd, and an older cluster employing Couchbase must switch to etcd prior to updating to the latest ClusterWare. See Appendix: Switching Between Databases for details.
The module API is intended to present a consistent experience regardless of the backend database, although some details, such as failure modes, will differ.
The server side (head node) responses to specific steps in the PXE boot process are controlled by the cluster configuration stored as JSON documents (aka objects) in the database. The following sections will follow the order of the boot steps described above to explore the definition and use of these database objects.
Internally, database objects are identified by unique identifiers (UIDs). These UIDs are also used to identify objects in ClusterWare command line and GUI tools, although as these strings tend to be cumbersome, an administrator should also assign a name and an optional description to each object. Even when objects are listed by name, the UID is available in the uid field returned by the object query tools.
Database objects generally consist of name-value pairs arranged in a
JSON dictionary and referred to here as fields. These fields can be
set via using the update argument of the appropriate scyld-*
command line tools or by editing object details through the GUI. Field
names are all lower case with underscores separating words. Not all
fields on all objects will be editable, e.g. node names that are assigned
based on the naming pool and node index.
Whenever a name-value pair is updated or added, a last_modified field in the mapping is also updated. These last_modified fields can be found scattered throughout the database objects.
Provisioning Compute Nodes¶
A principal responsibility of a head node is to provision compute nodes as they boot. A compute node's BIOS can be configured to boot from local storage, e.g., a harddrive, or to "PXEboot" by downloading the necessary images from a head node.
Each compute node is represented by a uniquely identified node object in the ClusterWare database. This object contains the basics of node configuration, including the node's index and the MAC address that is used to identify the node during the DHCP process. An administrator can also set an explicit IP address in the ip field. This IP address should be in the DHCP range configured during head node installation, although if none is specified, then a reasonable default will be selected based on the node index.
Each compute node is associated with a specific boot configuration, each stored in the ClusterWare database. A boot configuration ties together a kernel file, an initramfs file, and a cmdline, together with a reference to a root file system rootfs image. This rootfs is also known as a boot image, root image, or node image. A boot configuration also includes a configurable portion of the kernel command line that will be included in the iPXE boot script.
For a PXEboot, after the DHCP reply establishes the compute node's IP address, the node requests a loader program, and the ClusterWare head node responds by default with the Open Source iPXE loader, and a configuration file that identifies the kernel and initramfs images to download, and a kernel command line to pass to the booting kernel.
This kernel executes and initializes itself, then launches the init user program (provided by dracut), which in turn executes various scripts to initialize networking and other hardware, and eventually executes a ClusterWare mount_rootfs script, which downloads the rootfs image and sets up the node's root filesystem.
The mount_rootfs script may download and unpack a root filesystem
image file, or alternatively may mount an iSCSI device or
an image cached on a local harddrive, and then switch the node's root
from the initramfs to this final root image.
Other than when unpacking a root filesystem into RAM,
images are shared and compute nodes are
restricted to read-only access. In these cases compute nodes must use
a writable overlay for modifiable portions of the file system.
This is done toward the end of the mount_rootfs script via either the
rwtab approach (for example, see
https://www.redhat.com/archives/rhl-devel-list/2006-April/msg01045.html)
or more commonly using an overlayfs (see
https://www.kernel.org/doc/Documentation/filesystems/overlayfs.txt).